手把手教你安装Hadoop集群
手把手教你安装Hadoop集群
一、虚拟机安装与配置
注意,本文不适合小白操作,查看至少需要一点儿linux操作基础,因为其中有很多命令并没有写出来。比如使用vi修改文件后,需要使用:wq来保存并退出。
安装Hadoop集群时需要多个服务器,所以需要安装多个虚拟机,请自行安装。
配置服务器的hosts文件,就是将多个服务器之间建立域名配置(这样就可以使用域名来代替ip使用)。
1 | vi /etc/hosts |
最后添加如下内容(左边为每个服务器的ip,右边为主机名)
1 | 192.168.83.3 hadoop01 |
服务器ssh免密登录功能配置
服务器要开启ssh服务,一般的虚拟机都会自带的,如果没有,请自行安装
1 | ssh-keygen -t rsa |
输入上述命令后,不用输入任何东西,边按4次Enter键确认,会在root目录下生成一个包含有密钥文件的.ssh隐藏文件夹,进入目录可以看到有两个文件id_rsa.pub(公钥)和id_rsa。
1 | cd /root/.ssh |
使用命令直接复制到其他服务器上
1 | ssh-copy-id hadoop02 |
此时,在hadoop01机器上,输入ssh hadoop02或者ssh hadoop03时就可以免密登录服务器了
上述步骤需要重复,直到3个服务器之前都实现免密登录
二、Hadoop集群搭建
2.1 安装JDK,建议使用jdk1.8及以上(自行解决)
2.2 Hadoop安装
以2.10.1为例,进行安装
- 下载
- 可以到网页上下载 https://archive.apache.org/dist/hadoop/common
- 也可以直接使用wget命令下载
1 | wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz |
- 解压,我是直接解压到home里的
1 | tar -zxvf hadoop-2.10.1.tar.gz /home |
- 配置hadoop环境变量
1 | vi /etc/profile |
写入以下内容
1 | 配置Hadoop系统环境变量 |
然后执行以下命令使环境变量生效(centos下修改环境变量就是这3步,记住就好了)
1 | source /etc/profile |
- 使用如下命令可以查看是否hadoop安装成功
1 | hadoop version |
三、Hadoop集群配置
3.1 配置Hadoop集群主节点
在hadoop安装目录下的etc/hadoop目录下
- 修改hadoop-env.sh文件(如果配置了JAVA_HOME环境变量,这步可跳过)
1 | export JAVA_HOME=/usr/local/jdk/jdk1.8.0_341 |
修改core-site.xml文件
主要设置主进程NameNode运行主机和Hadoop运行时生成的临时目录
1 | <configuration> |
修改hdfs-site.xml文件
用来设置NameNode和DateNode两大进程,主要设置了Secondary NameNode 所在的服务的HTTP协议地址
1 | <configuration> |
修改mapred-site.xml文件
这个文件不是直接存在的需要从mapred-site.xml (1).template重命名过来。
cp mapred-site.xml .template mapred-site.xml
1 | <configuration> |
修改yarn.site.xml
配置让YARN用来做资源管理框架
1 | <configuration> |
修改slaves文件
用来配置hadoop中的集群,删除其中的localhost
1 | hadoop01 |
3.2 将集群主节点的配置方伯分发到其他子节点
3.1中完成的Hadoop集群主节点hadoop01的配置,还压根把系统配置文件、JDK安装目录和Hadoop安装目录分发到其他子节点hadoop02和hadoop03上,使用的scp命名,具体使用方法,可以自己了解下,不要直接复制下边的指令哈(如果不会用scp,自己手动把上边的步骤在每个服务器上做一遍)。
1 | scp /etc/profile hadoop02:/etc/profile |
四、Hadoop集群测试
4.1 格式化文件系统
1 | hdfs namenode -format |
或者
1 | hadoop namenode -format |
4.2 启动或者关闭Hadoop集群
可以单节点逐个启动和关闭,也可以用脚本一键启动或关闭
单节点逐个启动
- 在主节点上启动HDFS NameNode
1 | hadoop-daemon.sh start namenode |
- 在每个节点上使用以下指定启动HDFS DataNode 进程
1 | hadoop-daemon.sh start datanode |
- 在主节点上使用以下指令启动YARN ResourceManager进程:
1 | yarn-daemon.sh start nodemanager |
- 在每个从节点上使用以下指令启动YARN nodemanger进程:
1 | yarn-daemon.sh start nodemanager |
- 在hadoop02上使用以下指令启动SecondaryNameNode进程:
1 | hadoop-daemon.sh start secondarynamenode |
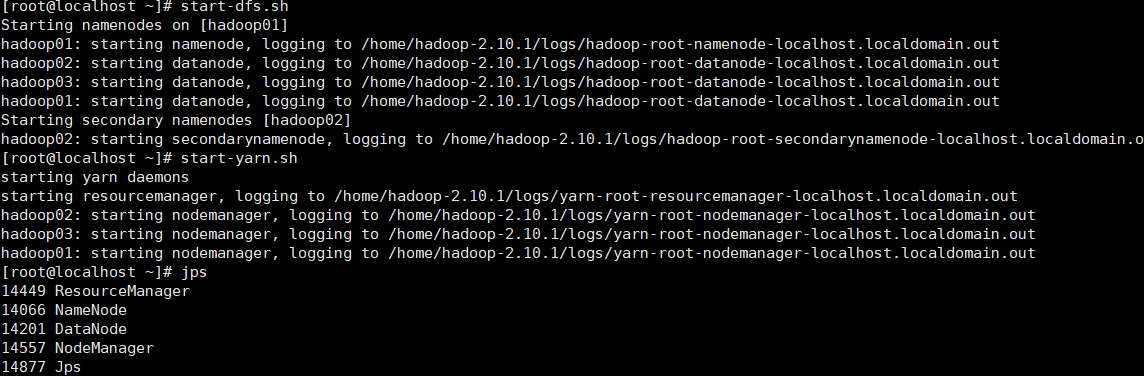
脚本一键启动
要求每个节点之前开启ssh免密登录,上文中有写
- 在主节点上使用以下命令启动HDFS进程
1 | start-dfs.sh |
- 在主节点上启动所有的YARN进程
1 | start-yarn.sh |
4.3 关闭Hadoop集群
不论是单个节点启动还是一键启动,只需要把上边的start换成stop就可以停止了
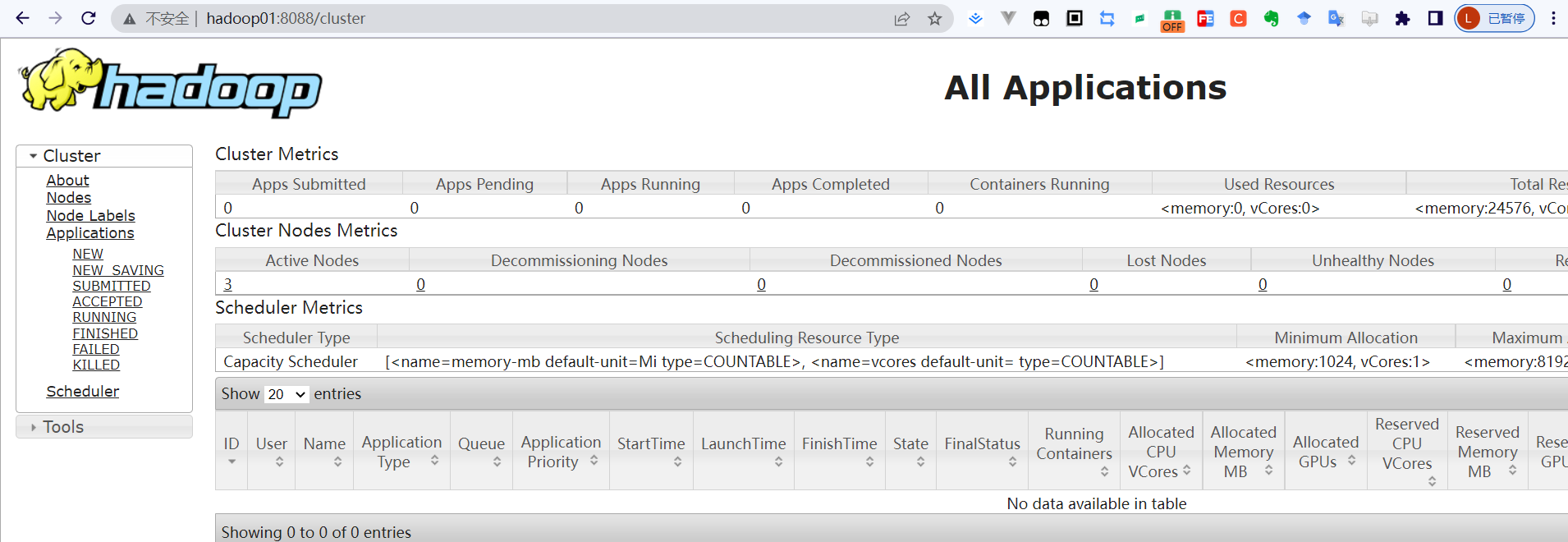
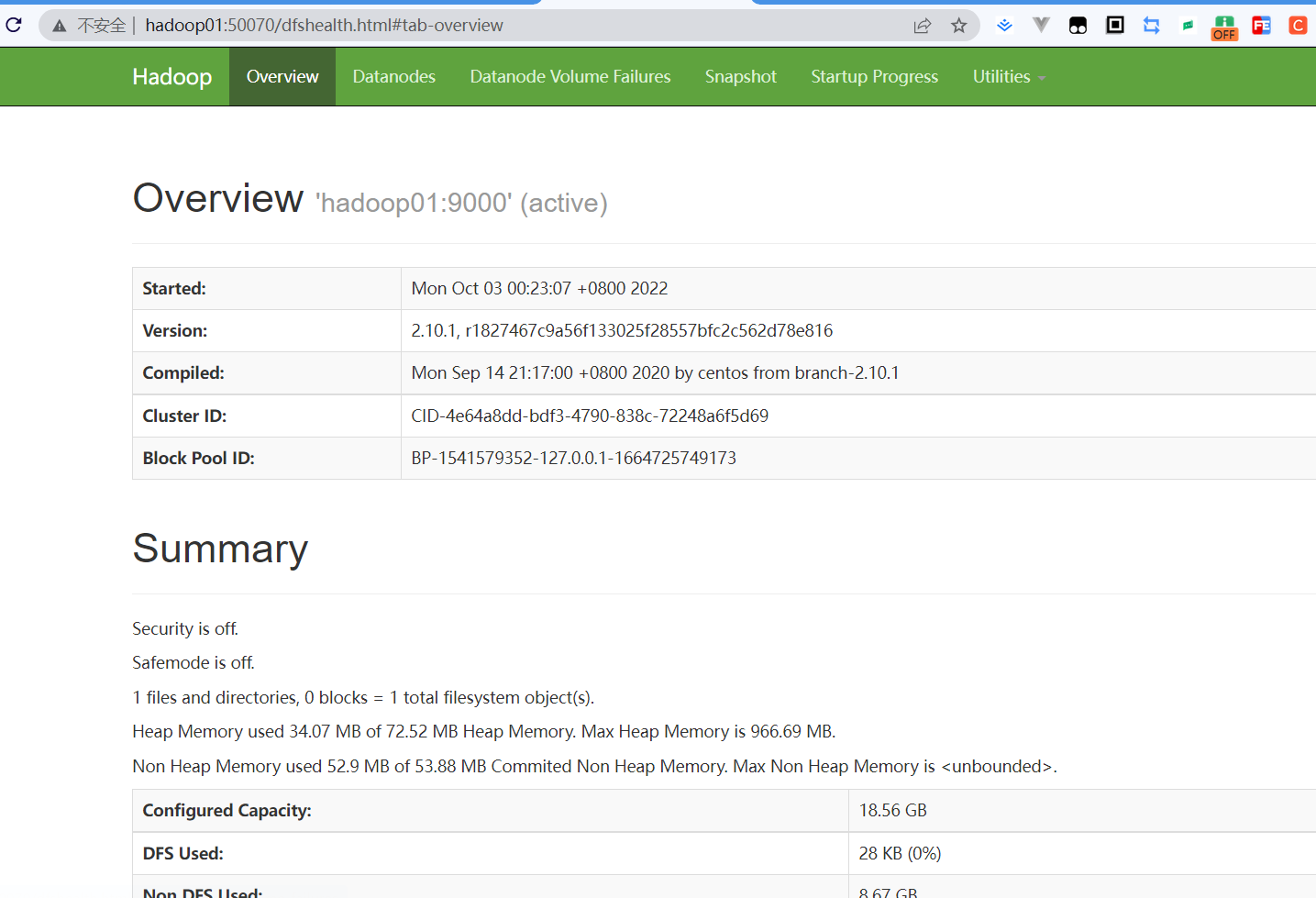
4.4 通过UI 查看Hadoop运行状态
注意在windows中的hosts中配置域名映射(内容和上边在虚拟机中配置的一样)。还有虚拟机上记得关闭防火墙放行50070和8088端口
然后在浏览器输入hadoop01:50070 和hadoop01:8088